Step-by-step Example
This chapter provides a step-by-step guide about how developers and final users can implement, deploy and execute a workflow using the eFlows4HPC HPC Workflow as a Service methodologies. The following video provide an overview of the required steps to port a workflows to the eFlows4HPC software stack. To illustrate it, we use the Pillar I workflow implemented during the first period of the project. Next sections provide a description of the workflow and a detailed description of the different steps.
Pillar I: Reduced Order Model workflow
Figure 19 shows an overview of what we want to achive with the Pillar I workflow. This workflow aims at creating a Reduced-Order Model (ROM) from the training data generated by Full Order Model (FOM) simulations. The HPC FOM simulations performed with the Kratos Multiphysics software are combined with distributed machine learning algorithms implemented with the dislib. The input for these simulations are available in HTTP repository, and the generated Reduce Order Model must be uploaded to the Model Repository in order to be available for final users. All required software will be deployed as containers in the HPC sites and all the required data movement and executions will be automatically orchestrated by the eFlows4HPC components.
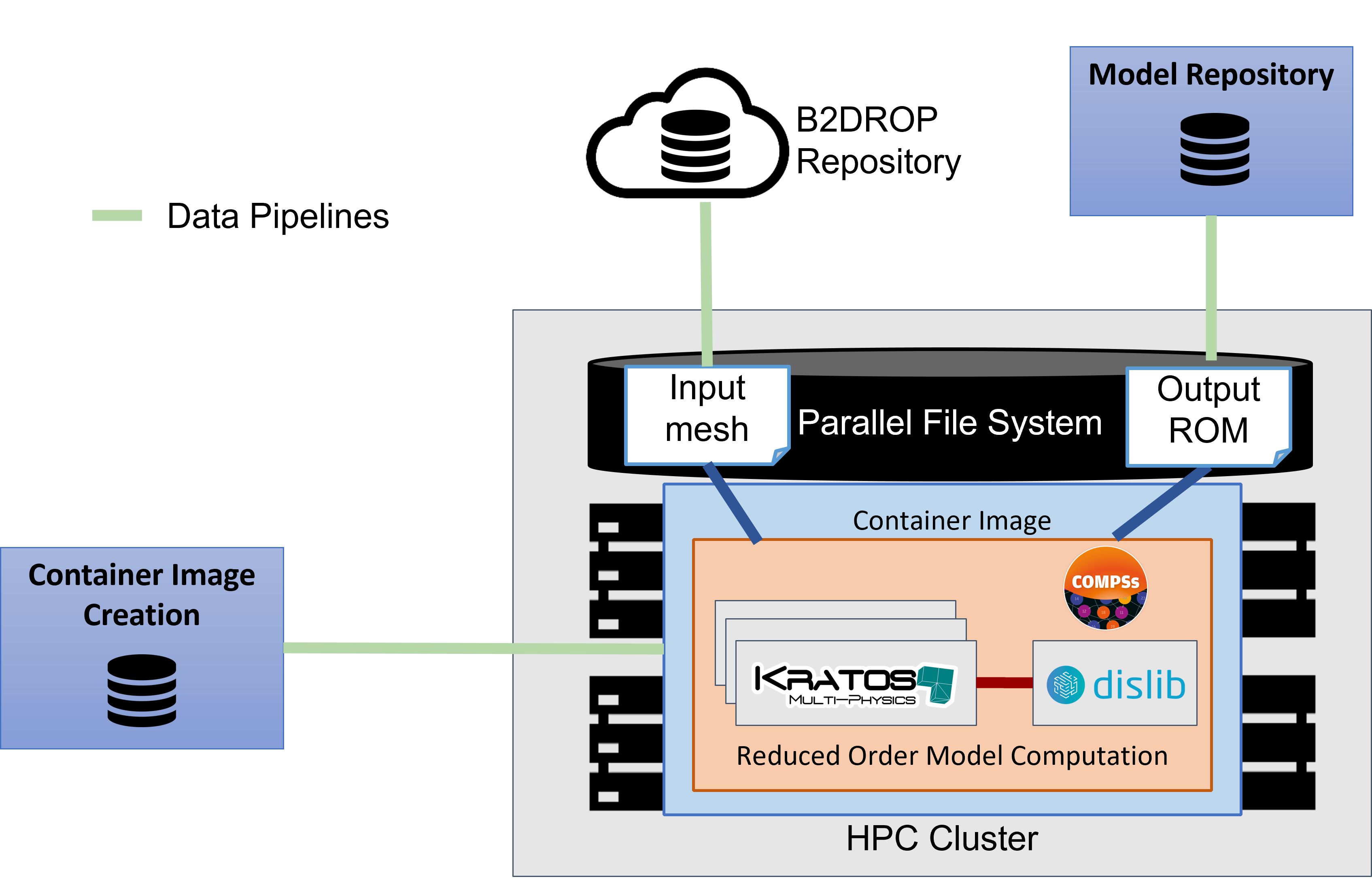
Figure 19 Overview of the Pillar I workflow.
The following sections describe the different steps to implement, deploy and execute the Reduce Order Model workflow using the eFlows4HPC methodologies:
Step 1: Implement the computational workflow integrating different types of computations using the eFlows4HPC programming interfaces.
Step 2: Enable the automatic creation of container images by including the workflow software requirements in the workflow description.
Step 3: Implement the data logistic pipelines to manage workflow data movements between the parallel file system of HPC clusters and external data repositories.
Step 4: Integrate the different workflow parts in TOSCA application to enable the automation of the deployment and execution processes.
Step 5: Deploy the workflow to an HPC clusters using Alien4Cloud and make it accessible to users
Step 6: Configure the credentials and Execute the workflow with the HPCWaaS execution API
This video shows how the eFlows4HPC HPCWaaS tools are used to import, deploy and execute the ROM workflow
If you want to see another example, the folloing video show how eFlows4HPC has been used for the Probabilistic Tsunami Forecast workflow.